I Was a CTO Who Couldn't Answer One Basic Question About My Own Team
I’m Jirka, one of the founders of Navigara. For about two years, I ran engineering, and there was one question I quietly hated:
Are we actually getting better?

Not “are we busy.” We were always busy. Busy is easy. Give a team enough meetings and Jira will look alive.
The real question was harder: is the team creating more value this quarter than last quarter, in a way I can explain outside the engineering room?
Then AI coding tools arrived in the budget. Copilot, Cursor, Claude Code, and the rest. Everyone said they felt faster. I believed them. I also knew that humans are not great witnesses to their own productivity. My calendar has lied to me many times.
A team can feel faster while creating more churn, more review load, or more code that has to be rewritten six weeks later.
That is an awkward thing to say after the company has already bought the tools.
I started in the wrong place.
Navigara did not begin as an engineering performance company.
We started closer to the individual developer. Career choices, market data, salary benchmarks, technical signals. We wanted to help engineers understand where they stood and what they were worth in the market.
The idea made sense until we hit the weak point under the whole thing.
Self-evaluation is noisy.
Not because developers are dishonest. Engineering work is just hard to describe. Some people oversell. Some undersell. Some people keep production alive for years and still say they are “pretty okay.” Others touch a framework for twelve months and start speaking like they invented it.
So we tried the usual fixes. Assessments. Take-homes. AI interviews. More process. More forms.
The signal was still weak.
The more we worked on it, the more obvious the real answer became: the person who understands your work best is usually the coworker who has been reading your code for months.
They know whether a diff was simple or dangerous. They know when a “small” change touched the part of the system everyone avoids. They know when a big pull request was mostly mechanical work, and when a smaller one quietly reduced risk for the whole team.
That was the first clue that we were solving the wrong problem.
The real problem showed up later.
Once AI coding tools became real spend, the question came back in a more expensive form.
Some engineers felt much faster. Some managers saw review volume go up. Some teams shipped more. Some teams mostly created more motion. All of those things can be true at the same time.
When an organization has 50, 500, or 5,000 developers, “people say it helps” is not enough. It is a placeholder.
At some point, finance, the CEO, or the board asks a simple question: are we paying for more value, or are we just adding another tool layer on top of the old uncertainty?
I remember versions of that conversation around planning and tool renewals. I could feel myself reaching for proxies I did not really trust. PR counts. Ticket flow. Manager anecdotes. Tool adoption. One suspiciously confident trend line.
None of it felt solid enough for a serious decision.
That was the uncomfortable part. I did not need a prettier dashboard. I needed an answer I could defend.
Our first version failed.
The first idea was obvious. Point an LLM at the work and ask it to judge the work.
Score this commit. Rate the impact. Rate the complexity. Rate the quality.
It failed in a very boring way. The scores came back almost flat. Everything looked average. The spreadsheet looked calm. The result was useless.
There was no number I would carry into a CFO conversation. There was definitely no number I would trust for a decision about a team.
The problem was not that the models were useless. We were asking them to do the wrong job.
What worked better was narrower. Ask the model to read the repo, understand what changed, place the change in context, and explain what likely happened.
That was the turn. The model stopped being the judge. It became the storyteller.
That changed the shape of the metric.
Once the model was giving context instead of a verdict, the system got more useful.
The story became structured input. Then a scoring system applied the same rules every time.
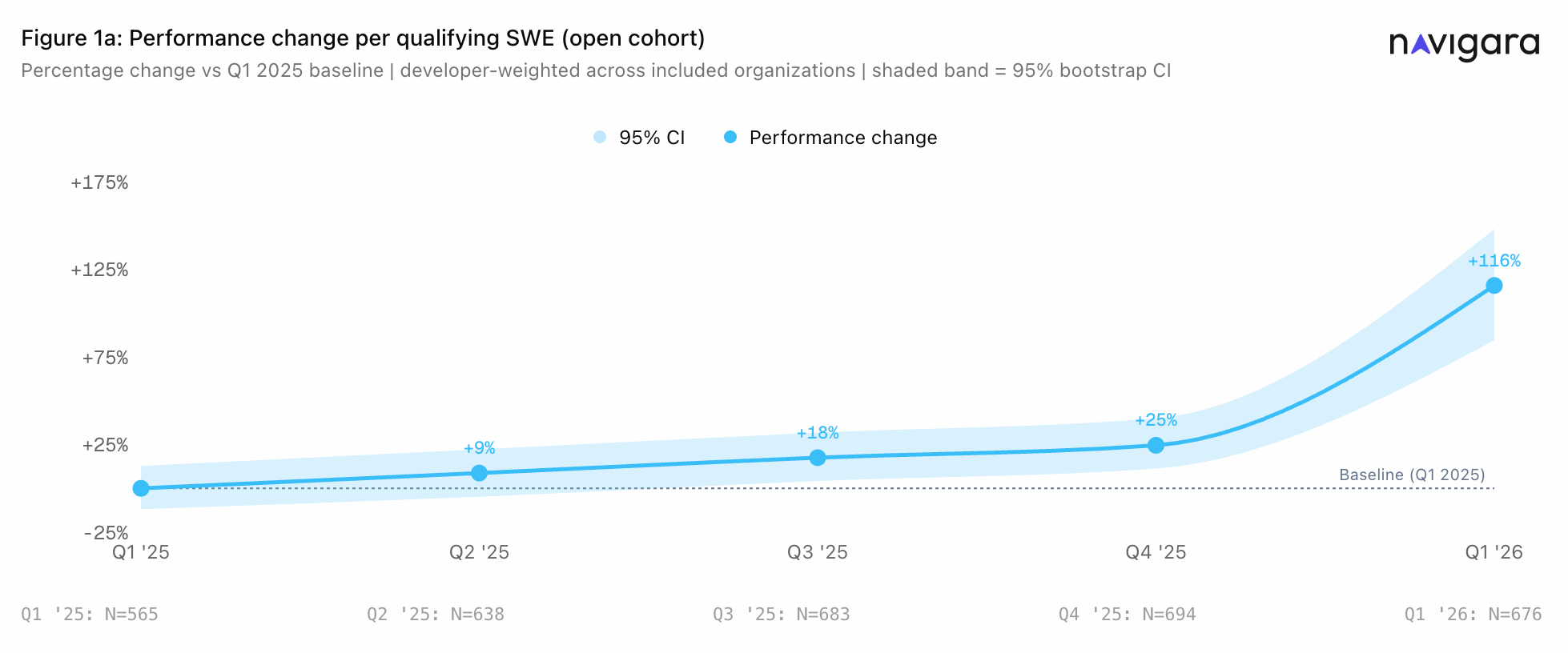
We call the result Engineering Throughput Value, or ETV.
ETV is not trying to summarize a person. That would be both impossible and a little creepy. It is trying to answer a narrower business question: what value appears to have shipped through the code, and how is that changing over time?
The output is split into Growth, Maintenance, and Fixes. That split matters. A team can ship more total work while doing less product work. Another team can look slower because it spent a quarter cleaning up a painful part of the system. Those are different stories.
The baseline matters even more. If you want to know whether AI changed anything, you need to compare the team against its own history. Same repos. Same people. Before and after the tools became part of normal work.

What this is and what it is not.
This is the section I would look for first if I landed here from Reddit, so I will be plain.
This is not a stack-ranking tool. ETV is a team and organization-level signal. The moment a metric becomes a leaderboard for individual worth, people start gaming it and the metric dies.
This is not the full truth about an engineer. Engineering includes design judgment, code review, mentoring, incident handling, product sense, architecture taste, and a lot of quiet work that does not fit into one number.
This is not “send us your code and trust us.” For teams with security or compliance limits, Navigara can run with an on-prem collector or fully on-premises / air-gapped. Your code does not have to leave your servers.
That matters because the surveillance concern is real. If a system like this is used to watch people instead of understand work, it becomes poison fast. The point is not to reduce engineers to a score. The point is to help leaders talk about engineering value without pretending ticket throughput is the same thing.
The thing I wish I had earlier.
Back when I was leading engineering, I wanted a way to answer a hard business question without hand-waving.
Is the team shipping more value than before?
Is the AI spend changing the work in a meaningful way?
Are we improving the system, or just making more visible activity around it?
I do not think every company needs a new metric for this. Some teams are small enough that the founders still read every pull request. Some orgs are early enough that AI tooling is still an experiment. Some cultures would misuse any number you gave them.
But if you lead a larger engineering organization, there is a good chance this question is already in your room.
That is the conversation I wanted this post to start. If it is useful, we can look at whether this can be measured in your environment.
Call with Jirka · 20 min
See if AI ROI can be measured in your org.
Book a direct call with Jirka Bachel to talk through your team size, AI tools, repos, and what a useful baseline could look like. No SDR.
Want to explore more?
See if AI ROI can be measured in your org.